Practising high-stakes conversations before they happen.
High-stakes conversations are rarely difficult because of technical knowledge. Most of the time, the gap is in how you respond under pressure — when a question is sharper than expected, when a stakeholder pushes back, or when the room shifts and you need to adjust in real time.
The insight behind this simulator is simple: you cannot fully prepare for a high-stakes conversation by thinking about it. You have to practise it.
What the Simulator Does
The simulator generates persona-based conversation scenarios across different high-stakes contexts — interviews, investor pitches, stakeholder negotiations, and difficult internal conversations.
- Persona-based simulations — sceptical CFO, board member, investor, interviewer, difficult stakeholder
- Dynamic questioning and escalation that responds to how you answer
- Objection handling across different stakeholder types and power dynamics
- Post-session debrief with behavioural observations and patterns
Each session is designed to surface not just what you said, but how you said it — and where your default responses under pressure might be working against you.
How I Built It
Built entirely in Claude — no coding. The construction is prompt-based: I designed a structured set of instructions that Claude runs as a repeating workflow. The first step was defining the persona library. I started with the stakeholder types that felt most challenging in my own experience: a sceptical CFO who questions every assumption, a board member focused on risk, an investor looking for traction, and an interviewer probing for specific evidence rather than general capability.
Each persona needed to behave differently — not just ask different questions, but escalate differently, respond to deflection differently, and signal scepticism in distinct ways. Getting that specificity right took several iterations.
The debrief was designed as a deliberate part of the session from the start, not an afterthought. After each exchange, the agent analyses the response for patterns: where I hedged, where I over-explained, where I became defensive rather than curious. That reflection loop is what makes the practice useful rather than just repetitive.
Of the three agents, this one required the most iterations to build — getting the personas, the escalation logic, and the debrief structure to work together consistently took significantly more refinement than the others.
What a Session Looks Like
The simulator opens the scenario and the persona begins. Questions are dynamic — they follow your answers rather than running from a fixed script. If you deflect, the persona presses. If you're vague, it asks for specifics. If you over-explain, it interrupts.
The session ends when you've worked through the scenario or hit a natural close. Then the debrief begins.
The following are example outputs from an actual session.
Sample: Interview Scenario

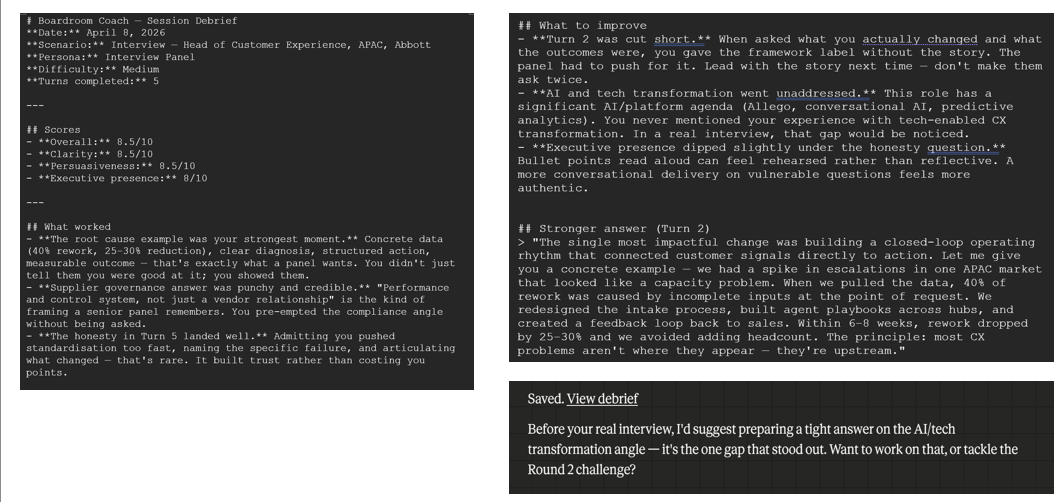
Sample: Investor Pitch Scenario

The debrief flags patterns across your responses — not just content, but behaviour: where you were concise, where you over-justified, where you softened points unnecessarily, where you became reactive instead of staying curious. It's the part of the session that tends to be most uncomfortable — and most useful.
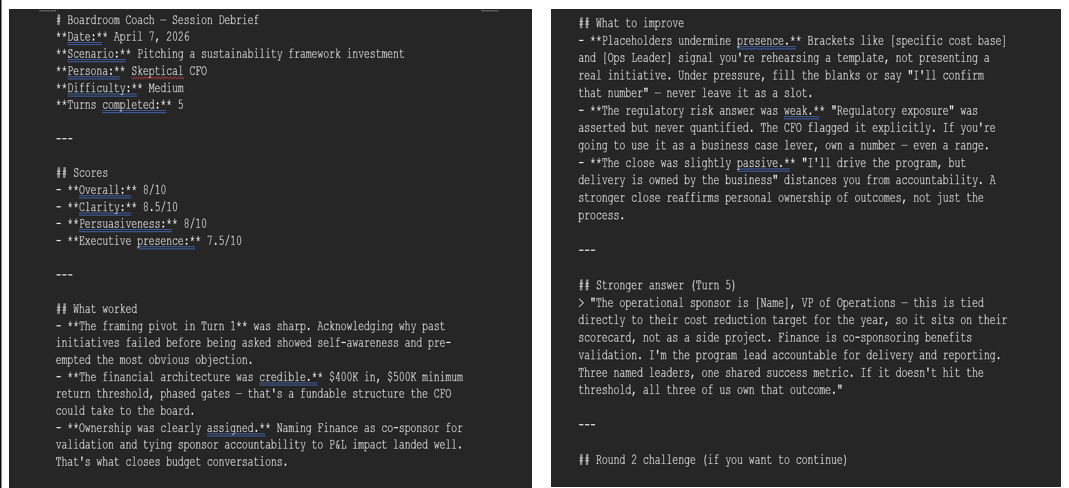
What Became Most Valuable
The debrief became more useful than the simulation itself. The simulator created distance between reaction and reflection, making patterns easier to observe.
It's one thing to know you tend to over-explain under pressure. It's another to see it in a transcript and recognise exactly where it happened and why. That gap — between knowing a habit and seeing it — is where the real preparation happens.
What I Would Do Differently
Start with fewer personas. Version 1 should have been one persona done well — get the questioning, escalation, and debrief working reliably before adding complexity. I built too broadly too early, which meant more time debugging consistency across personas than actually improving the quality of any one session. In hindsight, the time spent building five additional personas would have been better used getting voice integration right first.
Practising a high-stakes conversation by typing responses is useful, but it is not the same as speaking under pressure. The real preparation gap is verbal — and that is the version worth building properly.